Grandfather-Father-Son rotation schedule
System Integrity refers to keeping the system running as is, or at worst being able to restore the system to the way it should be after a catastrophe. This is where a system administrator really puts his money where his mouth is. Handling these situations well may be the difference between admiration and continued employment or flipping burgers. There are many levels as well as solutions to this problem but most fall into one of two categories: Redundancy and Backups. (think Parallelism and Caching)
Things that happen to disrupt system integrity...
rm -rf /tmp *
RAID (Redundant Arrays of Inexpensive Disks) first proposed by Patterson, Gibson and Katz at the University of California Berkeley in 1987 is a way of combining multiple disks into one array which the computer preceves as one drive and which yeilds performance better then just one single drive. The Mean Time Between Failure (MTBF) of the entire array would be equal to the MTBF of just one drive devided by the number of drives in the array. This makes the the RAID array undesireable from a maintenance perspective. Fortunatly, RAID allows for several fault-tolerent systems. Along with the built-in fault-tolerent systems in RAID, hot swappable drives can also be utilized. With hot swappable drives, the array does not have to be powerd down to replace a failed drive. The drive is simply replaced while the array is running and the RAID controller rebuilds it as needed. There were 5 levels of RAID originally proposed, since then other levels such as RAID-0 and RAID-1+0 has been commenly accepted.
Summary:
DNS provides a simple form of load balancing called round-robin rotation. Actually, it's more like connection balancing then true load balancing, but for many instances it can be very usefull.
A common use is to distribute login or CPU servers among several machines. For example, if you want to login to a Linux machine at the TCC, you can simply use the DNS name linux and DNS will give you one of four machines. The machine you get is not necessarily the least loaded one, simply the next one in the rotation. Here is an the entry in the DNS hosts file that makes this possible.
;
; Round-robin for Linux only machines
;
linux IN A 129.138.4.191
IN A 129.138.4.192
IN A 129.138.4.193
IN A 129.138.4.194
A common example is to have many ftp servers in a round robin
rotation. For sites that provide mostly download and little upload
this allows several machines to offset the load that would normally be
on one machine.
Primary and secondary DNS machines
DNS provides for primary, secondary, and caching servers. A primary server for a particular domain is the machine that holds the Start Of Authority or SOA record for that domain. Only one machine can have an SOA for a particular domain. For example, the primary name server for the domain NMT.EDU is prism.nmt.edu. and here is an example of it's SOA record.
nmt.edu. IN SOA PRISM.NMT.EDU. dan.PRISM.NMT.EDU. (
2000021001 ; Serial number (format yyyymmddii)
7200 ; Refresh (2 hours)
3600 ; Retry (1 hour)
604800 ; Expire (7 days)
604800 ) ; Keep/TTL(7 days)
IN MX 5 mailhost.nmt.edu.
IN NS PRISM.NMT.EDU.
IN NS NETPEEP.NMT.EDU.
IN NS DNS1.NMSU.EDU.
IN TXT "The New Mexico Institute of Mining and Technology, Information Systems Department, 505/835-5700"
The named.conf file looks something like this...
zone "nmt.edu" {
type master;
file "nmthosts";
};
zone "rcn.nmt.edu" {
type master;
file "rcnfiles/rcn";
};
A secondary server is a machine that can answer queries for a particular domain, but is not the final source of information for that domain. For example, netpeep.nmt.edu. is a secondary server for the NMT.EDU domain, and it's named.conf file might look something like this...
zone "nmt.edu" {
type slave;
file "zones/nmt";
masters {
129.138.4.216;
};
};
zone "138.129.in-addr.arpa" {
type slave;
file "zones/nmt.rev";
masters {
129.138.4.216;
};
};
A caching-only server is a machine that saves addresses as it sees them, but does not transfer entire zones from any other name server. This is useful for machines that do a lot of DNS resolves. For example the primary WWW server for NMT.EDU is a caching name server. This reduces the load on the primary name server and also reduces network traffic between the two. The named.conf file for a caching name server simply defines the root name servers and nothing else.
zone "." {
type hint;
file "named.ca";
};
Network Information Service (formally known as Sun Yellow Pages) was developed to do easily updated distributed information much the way DNS does. Where DNS did away with keeping /etc/hsots up to date, NIS did the same with files such as /etc/group, /etc/passwd, /etc/services and a host of many other such databases that, until before, had to be kept up by hand on each machine.
NIS works in a client/server environment where clients run daemons that bind to servers running similar daemons. It is through these daemons that information such as passwd file entries and even hosts are queried and/or updated.
NIS defines a domain, which is not necessarily the same as the DNS domain, to work in. Each domain is capable of containing its own databases, but unlike DNS the domains are not hierarchical.
Secondary NIS servers (called slave servers) work much like
secondary DNS servers. A machine is setup as a secondary server with
the ypinit -s <master> command, where master
is the NIS master server for that domain. Only the master can
actually update files, but any slave or master can respond to queries.
Usually the list of slave servers is kept in a text file that the
ypbind client daemon consults to choose a server to bind to. If done
properly, a failed NIS slave server will cause clients to rebind to a
different server providing rather effective redundancy.
Emergency Power
Ten years ago, the concept of uninterruptible power included diesel generators, racks of lead-acid batteries and strange colored electrical outlets designating which had emergency power and which did not. Even line conditioning, could get as complicated as incomming power running a motor that spun a magnet generating back power.
Today, for most applications, desktop UPS's do all that and more.
One of the most useful things modern UPS's can do is send a signal
to your computer when power has failed, allowing the computer to
shutdown before the battery runs out on the UPS.
Backups
Backups are the most common solution to System Integrity and can be
the easiest to overlook. As systems get larger and more complex,
backups need to increase in size, speed, and efficiency. This may
require another look at the how, when, what, and why backups are
being done.
The idea of backing up 100+ clients so all your user's work is secure is not a pleasant one. It is much more desirable to have only a handful of disks to backup. This means using file servers to export needed software to supported clients. While this tends to put all your eggs in one basket, it makes it much easier to backup the eggs. Plus, you can make this basked fault tolerant.
Next you need to decide what you really need to backup. Things like temporary work spaces definitely should not be backed up, but what about the base OS of each machine? Many times it is just as easy to reinstall from scratch then to restore from tape. Especially since you will probably need to bootstrap the machine anyway. A better system would be to have a script or list of programs that get installed after the OS. This is very helpful in rebuilding clients. Servers, should probably still be backed up. Even if they are easily reinstalled from scratch, it's usually much easier to restore /usr/sbin/in.named then to find it on the installation media.
Now what type of backup deviceses and media do you need? Media
such as DLT, 8mm, 4mm and QIC have different pros and cons, usually
centered around speed, space, and price. DLTs are very expensive, but
have a good price/MB ratio and work well in large-scale robots. QICs
are cheap and very useful for single client backup situations. Next
you need the drives themselves. Price, durability, and performance
should all be considered. Finally you may need special software to
perform your backups. For small situations, there are many free
programs available (tar, cpio, dump). For larger
situations you may require more professional software.
BRU from EST,
Amanda from Amanda,
and Networker from Legato, provide more sophisticated
procedures and differing levels of integration and support. Some
things to look for in backup software are, performance, platform
support, tape management, history database, data verification, simple
restoration, and support for common databases.
Rotation Schedules
Next you need to decide on a backup rotation schedule. Simply
using the same tapes to do a full backup every week will get you into
trouble the first time your tapes fail and you need a restore, or you
need a restore from two weeks ago. There are lots of different,
well-used schedules. Some of the more common are...
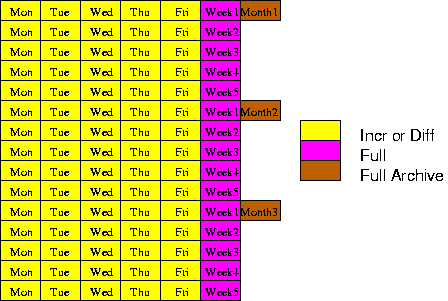
Grandfather-Father-Son
This method is probably the most common, and simplest to implement.
It has three basic levels, incremental or
differential, full and
archive. The first level is the incremental or differential; called
Son. For this level, there are usually four or five sets of
media labeled something like Mon, Tue, Wed and so on. These media are
used to backup the day that they are labeled for and recycle every four or five weeks.
The second level is the full backup called Father. There are usually four or five sets of these media labeled something like Week1, Week2 and so on. These media are used to do full backups on the week that they are labeled for and recycled every four or five weeks.
The third level is an archived full backup called Grandfather. These media are not usually recycled, instead they are archived by saving them in safe off-site permanent storage. The full backup is performed once every four or five weeks and marks the beginning of the next rotation period.
Grandfather-Father-Son rotation schedule
This method provides four or five weeks of backups with the ability to
recover from every day in that month, and a full every month in
permanent storage. This method uses about 10 sets of recyclable and
one set of non-recyclable media per rotation; four or five weeks.
Towers of Hanoi
In this rotation schedule each higher level of backup occurs on half
as often as the level below it. Lets say there are five levels of
backup labeled A through
E. Set A runs every other
day. Set B begins on the first
non-A day and repeats every four
days. Set C begins on the first
non-A, non-B day and repeats every eight days. Set
D begins on the first non-A, non-B, non-C day and repeats every 16 days, E should be obvious.
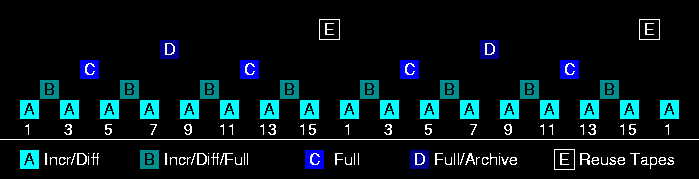
Towers of Hanoi rotation schedule
The rotation period for this schedule is very flexible because one can
simply choose how high the tower may get. The picture here shows a
rotation period of 16 days, but it could just as easily be 32 days.
This type of rotation schedule is usually used at smaller sites more
concerned with tape costs and immediate recovery then long term
storage. By way of comparison, a 32 day rotation peroid for the Hanoi
schedule uses 3 sets of recyclable and 2 sets of non-recyclable media
per rotation. However each set may be larger the than a set in the
Grandfather-Father-Son schedule.
Verification, Bootstrapping and Restoration
It doesn't do any good to backup all of your data and then find out that you cannot restore the data after a hard drive crash. So you need to make sure that your data is actually written correctly and can be read back off of your tapes. This process is called verification. Many backup programs offer some form of verification, but it is also wise to verify the data yourself. Occasionally restoring files and sometimes entire volumes of files is usually good verification practices. It is especially important after you have added another backup client or volume to your backup schedule.
The next logical step is to test the recovery of an entire client.
This usually involves some bootstrapping, or installing just enough of
the operating system and backup software to allow the rest of the data
to be restored. There are some commercial solutions to this, but many
times it is simple enough to have a boot disk or cdrom around or even
a network boot drive that can be used to bootstrap the machine.
Long-Term Off-Site Archival Storage
It is a simple enough concept but one that should be given
consideration. If all of your backup tapes are kept on one shelf in
your machine room, then all it takes is one careless construction
worker or a disgruntled employee to wipe out all of your backup
integrity. You can imagine if something really nasty like a fire or
flood could do. Thus the idea of off-site storage -- saving the
occasional backup tape to a safe archival location -- give you pretty
good security and piece of mind for the buck. Many sites utilize
something as mundane as a bank's safety deposit box, others have
multiple data centers around the world and rotate backup tapes on a
regular basis. Either way, you will want a secure off-site well air
conditioned location to archive some of your data in the event that
someone goes postal.
If Paranoia outweighs your purse then you may want to clone your
Full save sets. The idea of cloning is to make
a copy of the backup tape for off-site storage. This is usually done
just after the set finishes saving. Since the tapes are copied instead
just making another full save, there is no load on resources, and the
copy usually can be done in a fraction of the time the original save
took.
Most modern database engines such as Oracle, Sybase, and Informix cannot be backed up by
standard tools like tar or dump. These
engines write directly to their hard drives bypassing the operating
system. Even tools that read the data directly like dd
won't work because of sparse data. If you employ such database
engines it is important to look for solutions to back them up. Many
commercial backup software products have solutions for this, but even
if you don't have a vendor supplied solution there are still things
you can do.
A cold backup of a database is useful if you don't have a vendor
solution available and you don't need the database available 24x7.
The idea is to have the database write out all its table information
to a normal filesystem that the operating system can read and then
backup the written out data with normal backup procedures. This may
require the database engine to shutdown so that changes are not made
during the writing of the tables. Many database engines can import
their table data from a filesystem thus allowing this whole system to
work.
A hot backup is used if your database is needed 24x7 and/or you
can't afford the time and effort to write out tables to the
filesystem; which can take considerable time and space for large
databases. A hot backup requires the backup software to be aware of
the database engine you are using. The backup software will contact
the database and read information directly through the engine's
interface or in some cases read the data directly from the engine's
hard drives. Since most database engines are commercial and
proprietary, you will probably have to use commercial and proprietary
backup software to perform hot backups. In other words, you will need
to spend more money.
There is
one common feature to both of the Grandfather-Father-Son and Towers of
Hanoi rotation schedules that can be a serious drain on network
and/or cpu resources. Both schedules perform a Full backup of all data at one time, also known as a
Full Dump.
In this example there are five volumes, or sets of data, to be
backed up over a five day period. Each of the volumes may be one or
several disks spanning one or several servers. Some care should be
taken to try and balance the amount of data backed up each day. Each
day a full backup of one volume is made, such that
after the five day period all necessary data has been backed up. Each
day, incremental backups are made of all
volumes not slotted for a full backup. differential backups or a combination of the
two could be used instead.
Another common solution to increasing backup performance is to have
a separate network that is only used for backing up and restoring
data. This concept works well if the number of clients needed to
backup is small. Essentially, every backup client and server has an
additional ethernet card in it that is connected to a network of all
the other backup clients and the backup servers. There should be
nothing else on this network that generates traffic. This solution
will not help you if your cpu time is overloaded due to backups, but
it will take a lot of unnecessary traffic off your normal network.
local
Network
CatastrophicCloning Archives
Database Backups
Cold Backups
Hot Backups
Performance
Backup Schedules
Full Dump Backup Schedule
A Full Dump Schedule is the simplest backup schedule consisting of
a full backup of all data on one day and
incremental or differential backups on all other days. Most sites employ this method, but it
can have a serious drawback. Performing backups of several machines
at once can flood your network and degrade performance.
Staggered Backup Schedule
Staggered backups are often employed when backup resources are small
or computer/network performance is needed 24x7. The idea behind
staggered backups is to spread out the sometimes network and cpu
intensive full backup over a longer period of
time, thus reducing the performance hit to the network.

Staggered backup schedule
Backup Network
Disaster Recovery
Disaster recovery comes in many levels and forms, from reinstalling
the data on a hard drive, to getting things back on-line after a
building fire. All should be planned for and thought out ahead of
time. While it is true that things will never go quite the way you
planned for, having a plan ahead of time and using it will make your
life much easier, and get things working faster. Disaster recovery
can be organized into three major groups.
This type of recovery happens all the time, and is usually attributed
to either human error or simple hardware failures. Many times this
level of failure doesn't have a plan associated with it, although it
should. Also, things like RAID or clustering can make these
recoveries appear seamless to your users.
Usually a hard drive crashes or someone type rm -rf
where they shouldn't have.
This is similar to the last level, except the data is more critical.
Imagine the system drive crashing.
This involves replacing or rebuilding an entire machine, usually
due to hardware failures such as CPU or motherboard failing.
This is a larger level of failure involving several machines or network
equipment.
Usually due to hackers or runaway processes such as a temp cleaning
script.
Physical damage like lightning or flooding is a good example of this
one. Several machines get damaged and may need different levels
of recovery.
Once again, this is usually due to hardware failure, however
many installations can't recover from easily. The
price of networking equipment such as high-speed switches and routers
prevent many sites from keeping spare equipment handy. Many times,
the solution here is a bailing wire solution until new equipment
can be acquired.
This is the worst possible scenario, and usually is caused by
An alternate location with minimal equipment and staffing. Usually
required purchasing of equipment and lots of labor to return services
to normal. May take weeks.
A site that is regularly kept up to date with relatively recent equipment
and can be brought on-line in a matter of hours to days.
A site that is a duplicate of the downed site, with similar equipment
and staff ready to run at a moments notice.
Definitions of Terms